开云2026世界杯中国官网 视频AI卷向5分钟: 全量开源, 一次生成, 精良告别「盲盒抽卡」



编订|泽南、杨文
AI 视频生成,卡在长视频这说念坎上太真切。
以前一年,视频生成赛说念动作频频。谷歌推出 Veo 系列,并在本年 I/O 大会发布新一代多模态视频生成与编订模子 Gemini Omni Flash;字节的 Seedance2.0、快手可灵、阿里的欢娱马也一次又一次,冲破了咱们的预期。
各家模子生成的画面一个比一个顺眼,只能惜时长大多不特出 20 秒。一朝把视频拉长到分钟级,困难就来了,要么是消除扮装跨镜头后修葺一新,要么是说着说着声息变了或没了;念念改一个镜头,整条视频还得再行生成……
正因如斯,AI 长视频难以真实插足专科内容出产的职责流。
最近,一项开源的新本领却向咱们展示了一幅完全不同的图景。
先来看个 case。

注:本视频内容仅供学术盘考与本领测评办法使用,无谓于任何贸易用途。
皮克斯立场的 3D 质感归附得非常到位,动画细节处理也不恶浊。
弱点是,两分半钟里涵盖十余个镜头,近景对话、出息追赶、公路全景轮流出现,场景间过渡处理得很顺滑,且扮装形象能永久保合手一致,音画也同步当然。这绝对是一次性生成的。
这个视频,恰是出自京东近期开源的长音视频生成框架 JoyAI-Echo。
相较于市面上其他视频模子,JoyAI-Echo 有三大亮点。
它梗概完结长达五分钟的跨镜头「音视频双重一致」,保证扮装的面部特征和话语音色不变。
同期告别了以前「改一个镜头要重跑整条视频」的盲盒式生成,咱们不错径直通过当然语言指引 AI 进行局部修改,完结非线性裁剪与局部重绘。
此外,它守旧流式延迟不停下的两档及时超分,最高可径直输出 1472×2560 分辨率的高清视频与精细化音频,餍足专科级内容出产门槛。
目下,该模子的代码和权重文献均已公开,可免费下载使用。
GitHub:https://github.com/jd-opensource/JoyAI-Echo
神志主页:https://echo-team-joy-future-academy-jd.github.io/Echo-LongVideo-Page/
视频创作,无谓抽卡了?
JoyAI-Echo 还跑出了一大堆视频,个个特出两分钟,自带配音。

本视频内容仅供学术盘考与本领测评办法使用,无谓于任何贸易用途。
从视频中咱们不错看到, 模子精确归附了阴雨写实的哥谭氛围,蝙蝠侠从雨中屋顶的特写对话,到俯冲擢升、巷战、摩托追赶和仓库对持,场景平凡切换,但扮装外形、服装和环境立场永久谐和,莫得出现常见的立场漂移。
湿滑大地和动态朦胧收尾的处理,增强了动作戏的真实张力,雨声、脚步声、引擎轰鸣与对话也各占其位。

这类 vlog 视频,难点在于真实感。
穿牛仔的年青男人出当今多样场景自拍,开场手合手自拍杆的当然飘荡与行走圭表匹配当然,动作涌现,后续画面加入不同出镜者也莫得穿帮。
151 秒的视频画面中,男人面部详尽、发型、色彩与服装纹理保合手高度一致,车辆、行东说念主和室内枚举等环境元素在不同视角间也过渡当然。

前几段生成视频还靠场景和动作撑起视觉张力,而这段视频比的是紧密度。
画面中的东说念主物发丝、毛衣质感和环境光影都很真实当然,女生肢体姿态也涌现。
不外,在快速切镜时,配景细节偶有狭窄不一致,但不影响举座不雅感。
这么的阐扬,照旧把 AI 视频生成从 demo 和搞笑视频生成器推向了工业级出产用具的限制。
过往的视频生成本采取限于严重的时空崎岖文渐忘和失误积贮,很难用到故事创作、数字东说念主助手或及时内容生成等骨子场景中。而 JoyAI-Echo 展现出的跨镜头「音画双重一致性」,表现了 AI 照旧具备在万古序、复杂多视角下处理长篇扮装运转型叙事的能力,让 AI 真实有了讲好一个完整长故事的可能。
JoyAI-Echo 也重塑了创作家与 AI 之间的配合范式。由于能径直输出具备语义好奇和高准确率的台词对话,视频创作告别了「输入 Prompt、拼运说念抽卡」的被迫模式,在智能体和局部重绘机制的援助下,视频生成演进成了东说念主生动态配合的非线性裁剪的范式。
创作家当今不需要再为某一个穿帮镜头而将整条长视频推倒重来,极大地裁减了改稿资本,AI 梗概无缝地镶嵌到影视前期预演和动态分镜的职责流中。
那么 JoyAI-Echo 是若何作念到的?
若何攻克长视频生成难题?
从本领文书中咱们不错看出,JoyAI-Echo 在底层架构、数据清洗、多模态对皆及推理加快上有不少蜕变之处。
该框架通过两层互补的本领矩阵,攻克了长视频生成中万古一致性、高渲染延迟和低交互灵活性的行业难题。
百万级「身份向心型」语料,从起源处理变脸
以前,大模子拍视频容易翻车,很猛进度上是被喂进嘴里的数据给误导了。传统 AI 视频锻真金不怕火高度依赖优化单镜头质地的平铺式数据集,这就导致模子只学过短时辰内画面何如画才顺眼,但莫得线途经消除个扮装在不同期空、不同光影和服装下的视觉连贯性。
为此,JoyAI-Echo 构建了一套全新的身份向心型视频语料库(Identity-Centric Video Corpus),该活水线从电影、电视剧和长网页视频中,精确索求出了特出 100 万个私有的扮装身份原型,再经过全局原型与时空去重,世界杯开云多轴质地过滤与流跟踪,紧凑型音视频聚会标注,为模子生成内容的一致性提供了保障。
「槽位配对」追念机制,给面部和声息上双保障
在模子架构上,JoyAI-Echo 毁灭了径直的端到端生成,转而弃取基于渐进演化追念库(Evolving Memory Bank)的迭代分镜合成机制。其中枢本领在于想象了「槽位配对(Slot-Paired)」音视频追念交互机制。
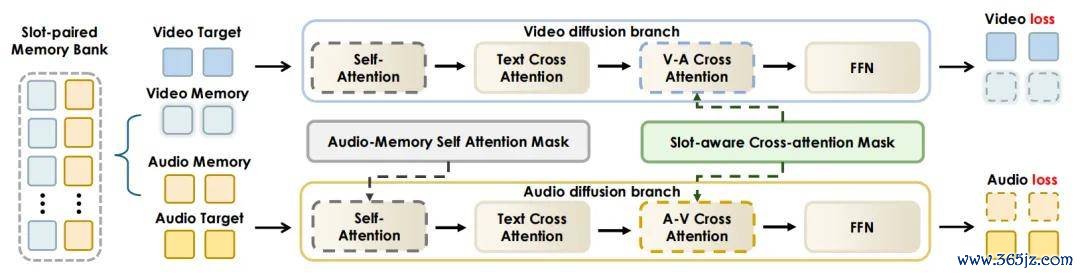
槽位配对视听追念交互机制概览。
它非常于给每个扮装的脸和声息进行了径直绑定。其中,每一个历史事件都包含对皆的视觉和音频追念符号。在生成阶段,地点视频和音频符号由两个扩散分支进行处理,而追念符号仅看成条件崎岖文使用,不参与赔本狡计。在音频分支中,「音频 - 追念」自夺目光掩码完毕着地点音频符号与音频追念符号之间特定层级的交互。
在跨模态模块中的「槽位感知」跨夺目光掩码,强制完结了配对的视觉与音频追念槽位之间的逐一双应交互,从而胡闹了跨事件的东说念主脸与声息稠浊。
由此,该模子在仅量度刻下视频和音频地点的同期,依然梗概保合手长程的视觉身份一致性及话语东说念主音色的一致性。
后锻真金不怕火体系:嘴型对得准,推理快 7.5 倍
为使底层架构开释最大后劲,盘考团队想象了一套按部就班的后锻真金不怕火体系。
开运体育中国官网入口长崎岖文赔本重定向与梯度放大(控口型):由于长崎岖文会让语音运转面部变得更困难,在基础锻真金不怕火阶段,视频赔本权重会凭据刻下的追念槽位长度进行为态调大,胡闹口型同步退化。同期,音频到视频的交叉模态梯度在 forward 不变的前提下被放大(二阶段放大至 6 倍),显耀强化台词对嘴型的完毕力。
多分辨率渐进式 SFT(提画质):将单镜头高清样本与概大肆采样的多镜头语料交融 fine-tune。弃取 480p 到 720p 渐进式分辨率转念,在增强单镜头与长视频画面质感的同期,齐备秉承了多镜头一致性能力。
OmniNFT 跨模态对皆强化(RLHF 对皆):针对多模态强化学习中「音画奖励不一致」、「视频梯度稠浊浅层音频收罗」以及「对皆孝敬度分拨不均」三大瓶颈,JoyAI-Echo 引入了 OmniNFT 框架。它完结了模态特异性上风路由(寂寞分发视觉、音频、同步奖励)、层级梯度手术(在浅层音频收罗断开视觉梯度,在深层保留交互),并讹诈视听交叉夺目光图谱看成内在代理,对发声弱点区域扩张局部赔本重绘。
双向与因果 DMD 蒸馏(加快):为了透彻甩手生成要津冗长的硬件遭殃,团队弃取分散匹配蒸馏(DMD)将多步双向生成器压缩为 8 步学生模子,且在锻真金不怕火时间均衡视听赔本通盘,通过 EMA 优化器动量缓冲平滑音频 gradient 噪声。值得热心的是,DMD 锻真金不怕火中加入了追念输入左迁模拟(Degradation),特意模拟长序列滚出时自生成历史产生的漂移,使模子对邪恶积贮具备极强的鲁棒性。该架构还能当然延长至块状因果流式生成(Causal Streaming Generation),完结从全崎岖文去噪到因果流式生成的无缝过渡。
在生成模子之上,JoyAI-Echo 又加入了两个让工业落地成为可能的模块。
智能导演智能体(Director Agent)传统的视频用具是「一次性输入、盲盒式抽卡」。而该智能体引入了「用具与技巧抽象」职责空间,能把用户的朦胧需求自动细化为包含扮装卡、场景卡、分镜时长的结构化脚本。它讹诈 KOK(弱点镜头的弱点帧)计谋索求动态追念条款。创作家若是对某个镜头不温顺,只需用大口语在评审阶段建议修改倡导,智能体就会自动定位并针对该镜头进行局部重绘和追念更新,整条长视频无需再行生成。
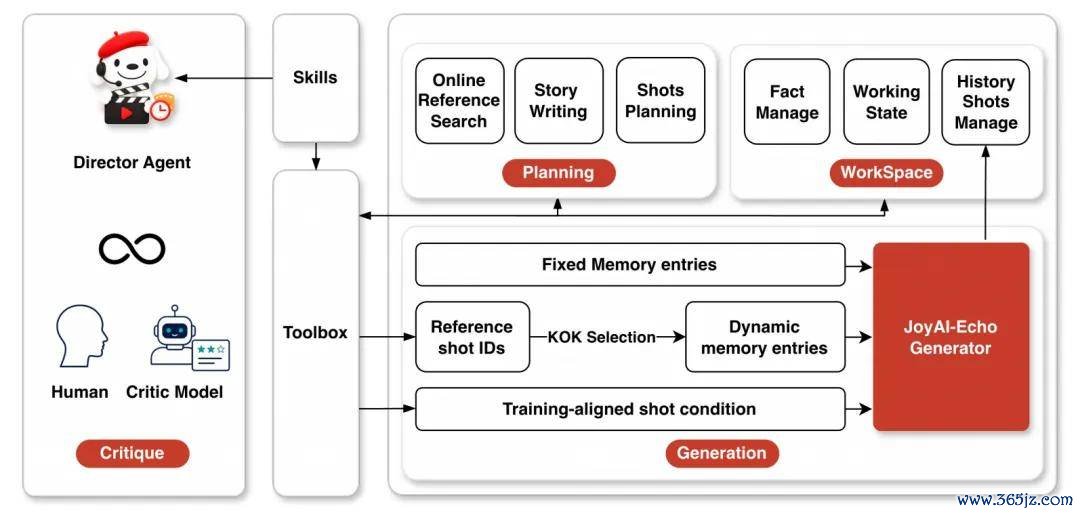
导演智能体(Director Agent)职责流概览。该智能体将长篇视频的生成过程永诀为狡计、生成和评审三个阶段,守旧讹诈局部反映进行非线性修改,再通过单步超分收罗进行高画质输出。
聚会单步超分架构(Unified One-Step SR)则将空间放大的算力遭殃从自记忆过程中透彻解耦。依托超 87 万顶级视听语料,自研了 CondSRPatchifyProj 轻量级模块。它仅需单个扩散流前向要津,就能将 720p 潜在空间径直扩展至 1152×1920(1K) 或 1472×2560(2K)的高清视听 Token 空间,在守护流式极低延迟的同期,大幅拉高了成片的细节好意思学。
通过在包含 100 个脚本故事、3000 个规矩镜头(跨动漫、写实立场、含指定 IP 与原创扮装)的超永生成基准评测集上进行测试,JoyAI-Echo 的各项狡计均位列前茅:
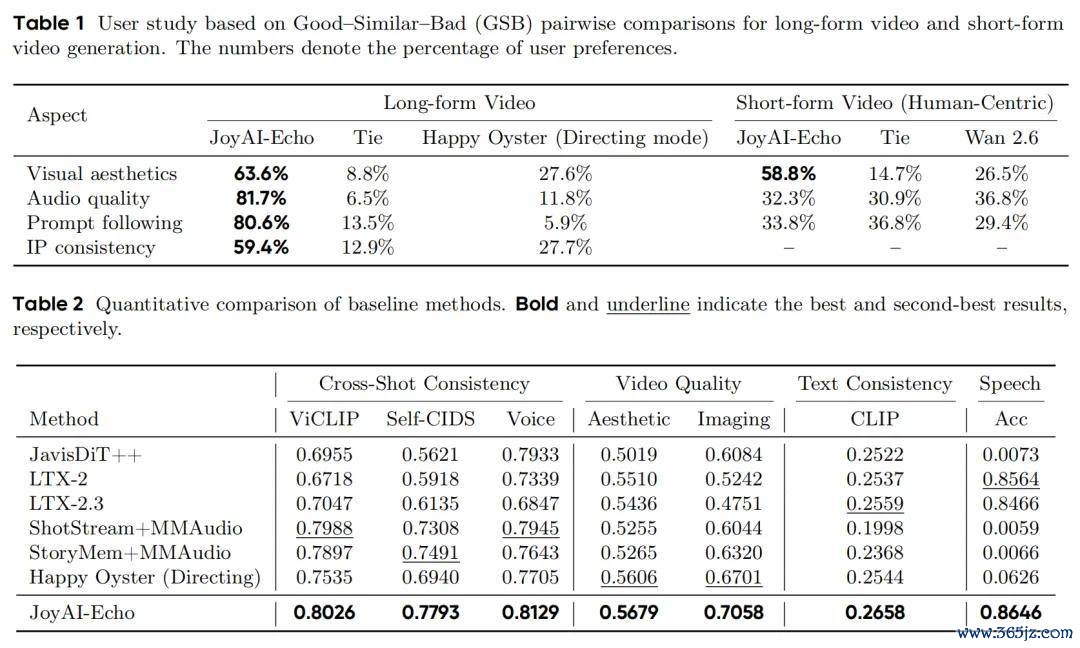
可见,JoyAI-Echo 在视听一致性方面保合手率先,台词准确率达到了 0.8646,在终末成片的盲测偏好与短视频能力上都相当优秀。
结语
JoyAI-Echo 的出现像是一个信号:长视频生成,终于从「能用」迈向了「好用」。
在此之前,AI 长视频生成的瓶颈,一直卡在时辰维度上的连贯性,也即是一个扮装能弗成在五分钟里永久是消除张脸、消除把声息,一段内容能弗成像真实拍摄那样经得起反复打磨和局部修改。这些问题,决定了 AI 视频能否真实插足专科内容出产的职责流,照旧持续停留在演示层面。
JoyAI-Echo 用跨模态追念库、追念运转后锻真金不怕火和 Director Agent 三套机制,给出了处理决议。
更值得热心的是开源这个弃取。代码与权重的全量洞开,意味着这套处理决议不会锁死在某一家公司的家具范畴里。建造者不错在此基础上针对垂直行业进行二次建造,内容创作家不错将其接入我方的用具链,盘考社区不错在公开的本领底座上持续鼓励。这种洞开自己,每每比模子自己更具永恒价值,它把一项本领突破,形成了通盘产业不错共同搭建的基础设施。
从谷歌、字节、快手到阿里、京东,视频生成赛说念的竞争从未住手,拼完画质拼时长,拼完时长拼一致性,下一站,很可能是谁能先把东说念主机配合式创作这件事作念通。
JoyAI-Echo 的 Director Agent开云2026世界杯中国官网,恰是在这个方进取迈出的一步。当咱们不错用对话的时势指引 AI 修改某一个镜头,视频创作的门槛就不再是用具的使用难度,磨真金不怕火的是创作家我方的念念象力。
 备案号:
备案号: